上一步完成了维度建模:数据仓库之维度建模 | 62bit的秘密基地
这一步把数据统计后存入MySQL(ADS层),然后用python的matplotlib包对数据进行可视化
DW to ADS
导包
1
2
3
4
5
| <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
|
配置hive和mysql
1
2
3
4
5
6
7
8
9
| val conf = new SparkConf()
.setAppName("ADS")
.setMaster("local[*]")
val spark = SparkSession.builder().config(conf)
.config("hive.metastore.uris","thrift://192.168.52.120:9083")
.config("spark.sql.warehouse.dir", "hdfs://192.168.52.100:8020/user/hive/warehouse")
.config("spark.jars.packages","mysql:mysql-connector-java:8.0.27")
.enableHiveSupport()
.getOrCreate()
|
处理数据,统计各分区总播放量和总收藏数以及子分区总播放量和总收藏数
这里的spark sql会默认使用hive而不是mysql,很神奇
1
2
3
4
5
6
7
8
9
10
11
| spark.sql("use bilibili_dw")
val df = spark.sql("select video_data.play, video_data.favorites, dim.subpartitionId, dim.partitionId " +
"from dim join video_data " +
"on dim.id = video_data.id;")
var df1 = df.groupBy("partitionId").sum("play","favorites")
var df2 = df.groupBy("partitionId","subpartitionId").sum("play","favorites")
val partitionDF = spark.sql("select * from bilibili_dw.partition_id")
val subpartitionDF = spark.sql("select * from bilibili_dw.subpartition_id")
df1 = df1.join(partitionDF,"partitionId").drop("partitionId")
df2 = df2.join(partitionDF,"partitionId").drop("partitionId")
.join(subpartitionDF,"subpartitionId").drop("subpartitionId")
|
建库,需要设置编码和排序规则,否则在保存数据时会报错
1
| CREATE DATABASE bilibili_ads CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
|
保存数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| df1.write
.format("jdbc")
.option("url", "jdbc:mysql://192.168.52.120:3306/bilibili_ads")
.option("user", "xxxx")
.option("password", "xxxx")
.option("dbtable", "partition_data")
.mode("overwrite")
.save()
df2.write
.format("jdbc")
.option("url", "jdbc:mysql://192.168.52.120:3306/bilibili_ads")
.option("user", "xxxx")
.option("password", "xxxx")
.option("dbtable", "subpartition_data")
.mode("overwrite")
.save()
|
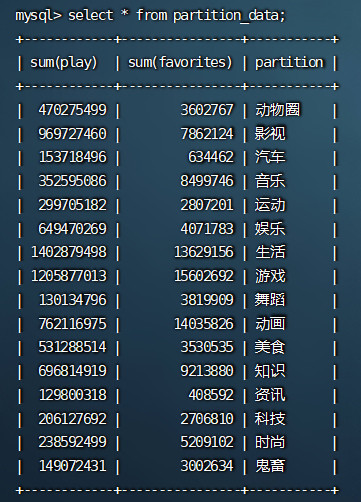
然后可以在mysql中查到这两张表
遇到的坑
- Spark Session同时配置hive和mysql后,执行spark sql时默认使用hive,如果想操作MySQL的数据库,需要在表名前加上MySQL的数据库名或别名,或者在Hive中创建一个外部表来映射MySQL的表。
- 创建表时配置了编码格式,但还是会报错,原因是数据库的编码格式并没有改变,需要去设置数据库的编码格式
数据可视化以及数据分析
从热门程度的角度分析
收藏量可以反映视频值得反复观看的价值,播放量可以反映视频的受欢迎程度,用这两个指标来数据分析
python获取ADS层的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import pymysql
import matplotlib.pyplot as plt
db = pymysql.connect(host="192.168.52.120",
user="xxxx",
passwd="xxxx",
db="bilibili_ads")
sql1 = "select * from bilibili_ads.partition_data"
sql2 = "select * from bilibili_ads.subpartition_data"
cursor = db.cursor()
cursor.execute(sql1)
partition_results = cursor.fetchall()
cursor.execute(sql2)
subpartition_results = cursor.fetchall()
db.close()
|
可视化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
partition_cols = list(map(list, zip(*partition_results)))
subpartition_cols = list(map(list, zip(*subpartition_results)))
plt.rcParams['font.sans-serif']=['SimHei']
plt.scatter(partition_cols[0], partition_cols[1], s=10, c='b', marker='o', alpha=0.5)
plt.xlabel('播放量')
plt.ylabel('收藏量')
plt.title('分区播放量-收藏量')
for i in range(len(partition_cols[1])):
plt.text(partition_cols[0][i], partition_cols[1][i], partition_cols[2][i], fontsize=10)
plt.show()
plt.scatter(subpartition_cols[0], subpartition_cols[1], s=10, c='b', marker='o', alpha=0.5)
plt.title('子分区播放量-收藏量')
for i in range(len(subpartition_cols[1])):
plt.text(subpartition_cols[0][i], subpartition_cols[1][i], subpartition_cols[3][i], fontsize=10)
plt.show()
|
结果
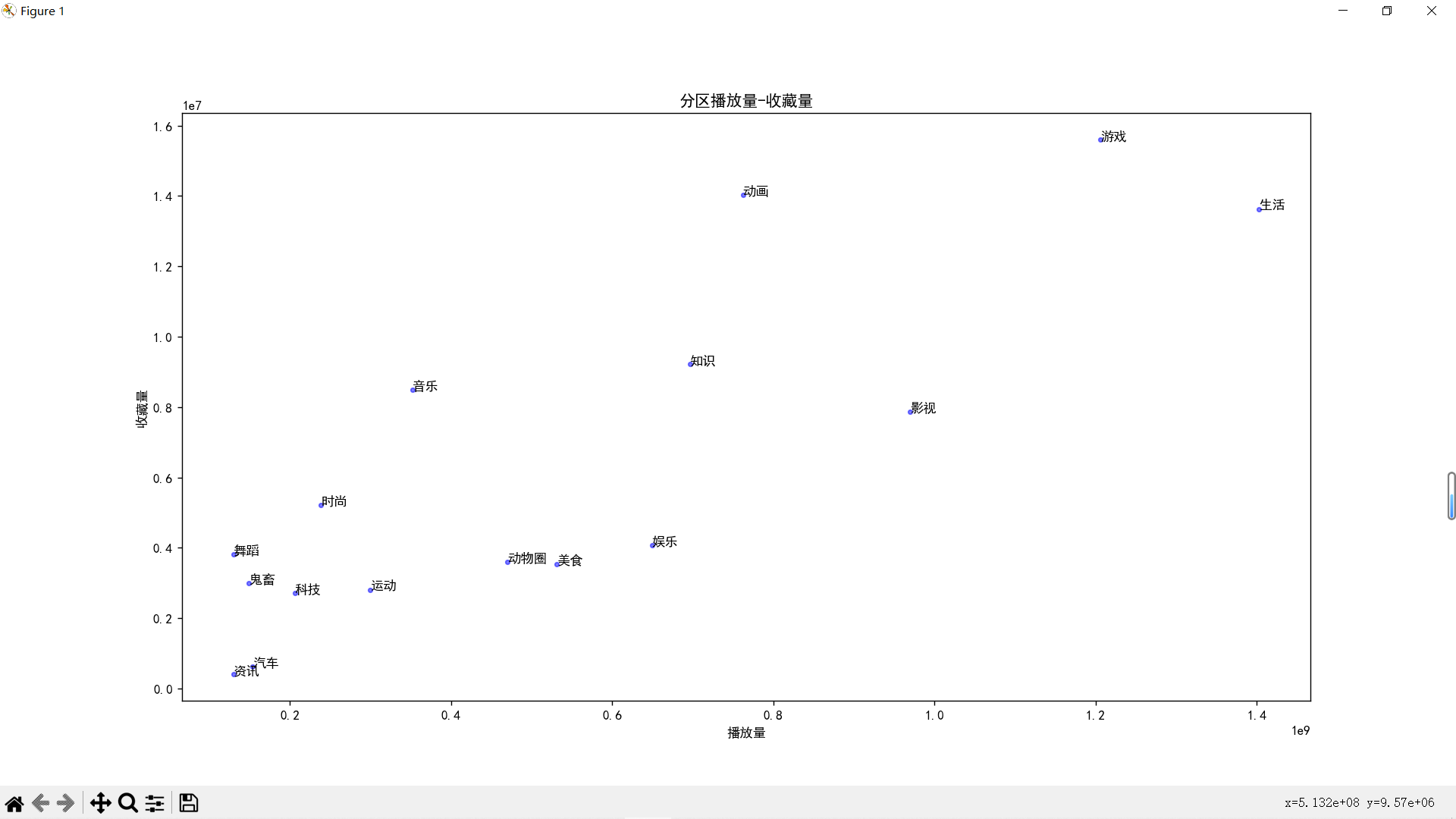
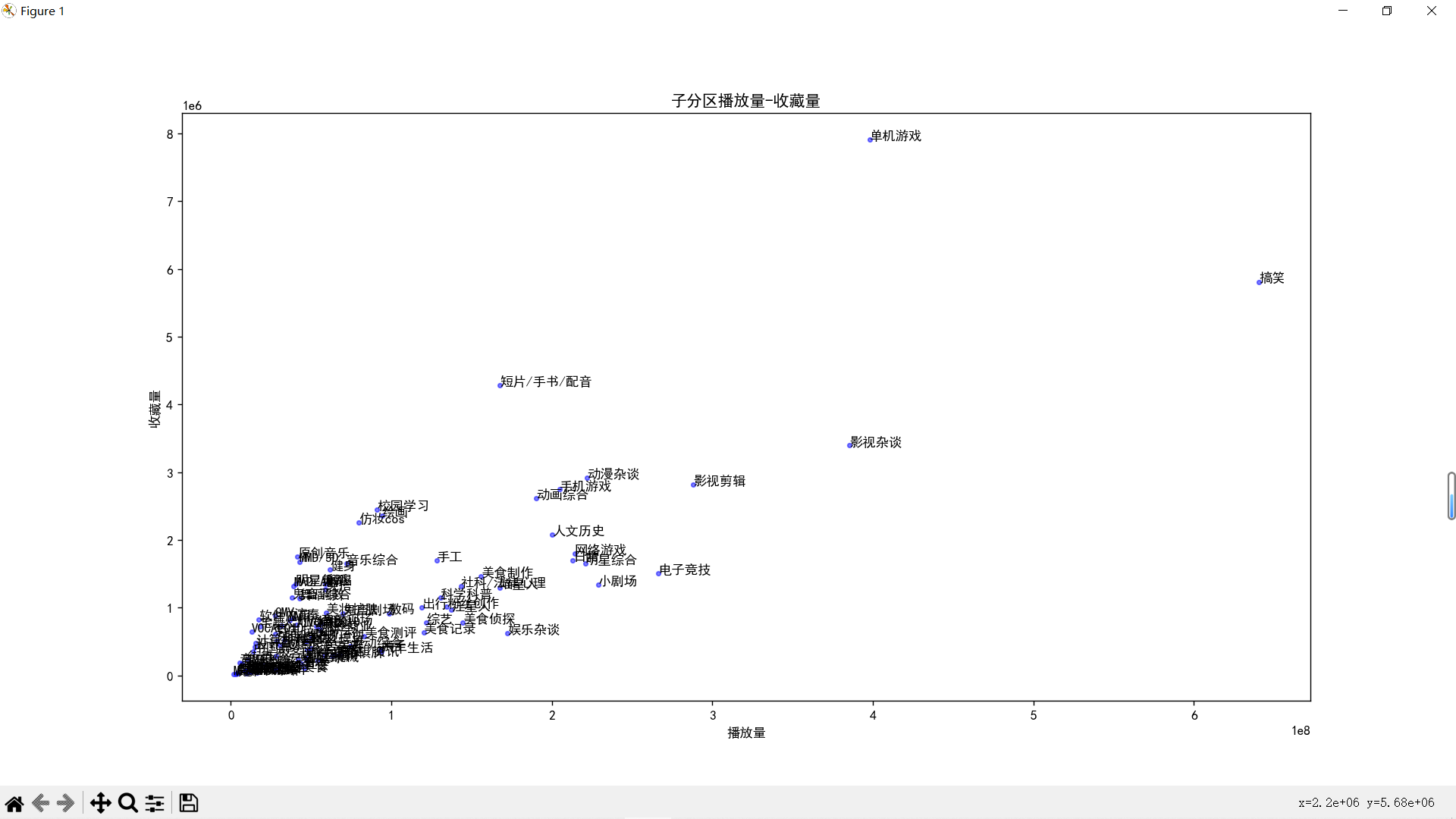
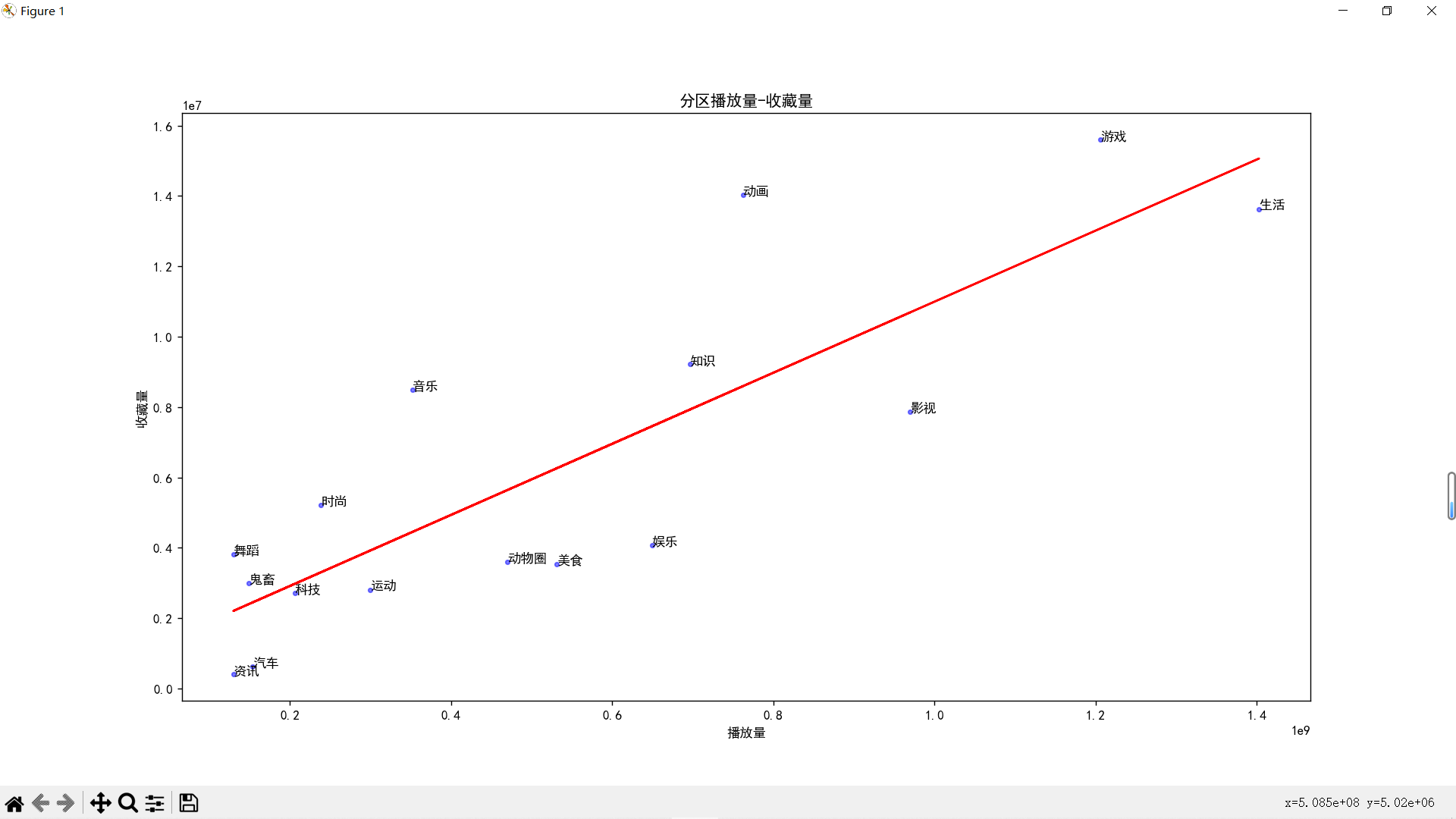
生活区和游戏区两大巨头,动画区、知识区和影视区紧随其后,完全符号我对B站的全部想象(ˉ﹃ˉ)
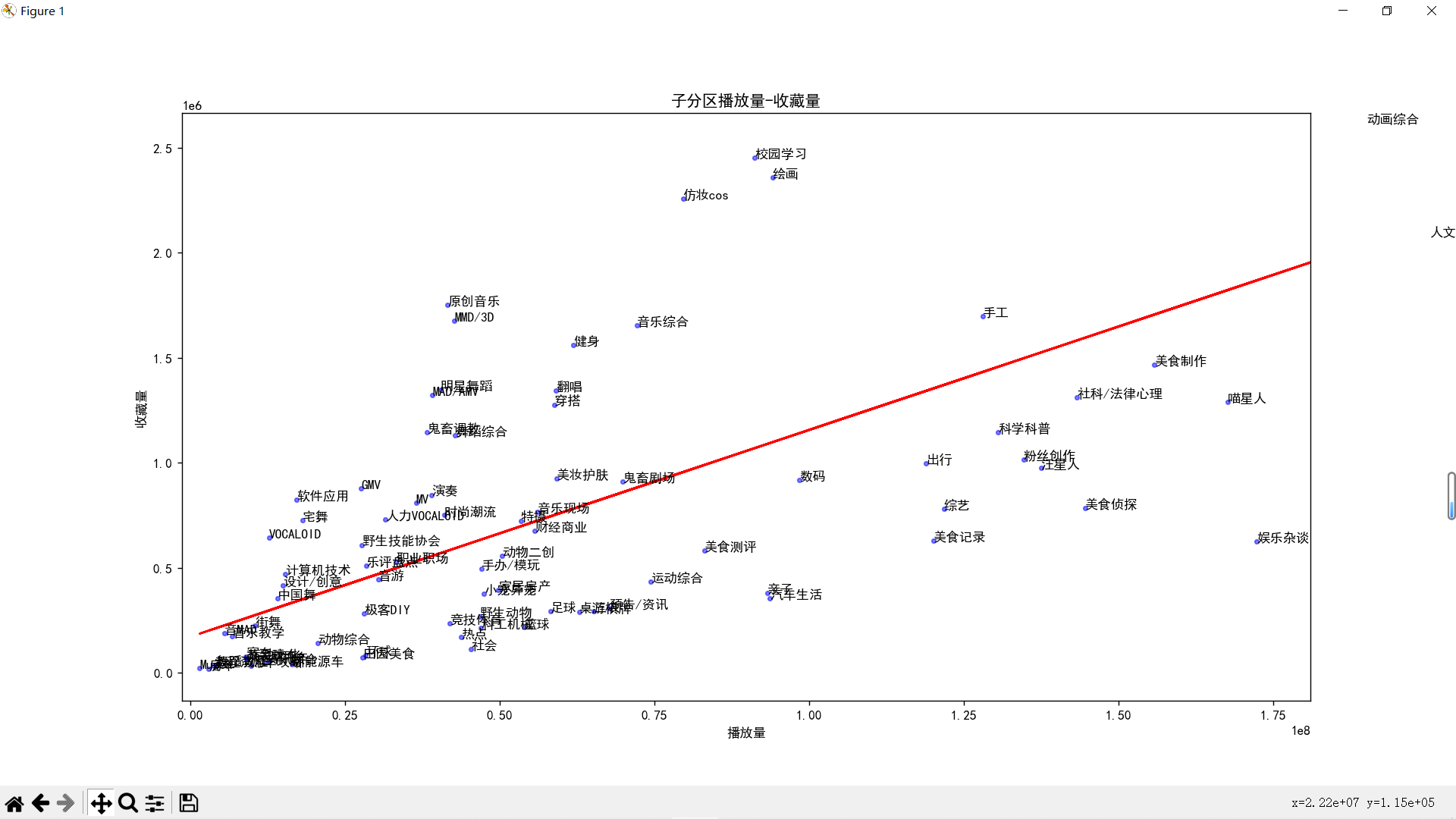
再来放大左下角
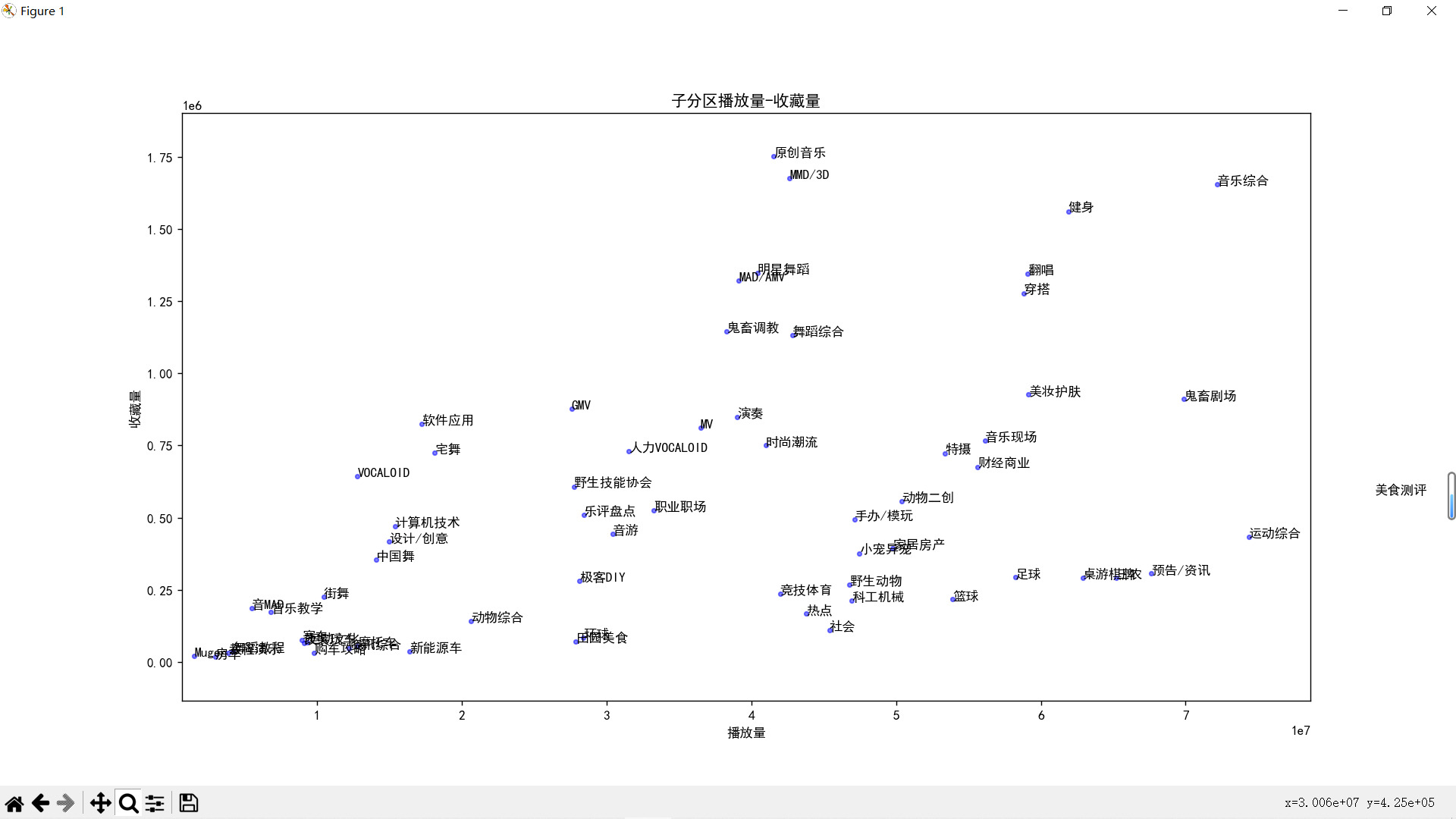
可以看到现在的b站已经是生活游戏搞笑唠嗑乐子人的天下了,反而是于二次元相关的音MAD,宅舞,VOCALOID、鬼畜等分区成了吊车尾,mikufans一败涂地!不禁让我想起了那句话:“你们二次元没有自己的网站吗?”
从视频收藏价值的角度分析
再根据播放量和收藏数拟合出一条一维曲线,这条曲线表示播放量和收藏数的关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import numpy as np
from scipy.stats import linregress
z1 = np.polyfit(partition_cols[0], partition_cols[1], 1)
p1 = np.poly1d(z1)
print("播放量和收藏量的拟合一次多项式:", p1)
r1 = linregress(partition_cols[0], partition_cols[1])[2]**2
print("R方:", r1)
plt.plot(partition_cols[0], p1(partition_cols[0]), 'r', label='拟合曲线')
z2 = np.polyfit(subpartition_cols[0], subpartition_cols[1], 1)
p2 = np.poly1d(z2)
print("播放量和收藏量的拟合一次多项式:", p2)
r2 = linregress(subpartition_cols[0], subpartition_cols[1])[2]**2
print("R方:", r2)
plt.plot(subpartition_cols[0], p2(subpartition_cols[0]), 'r', label='拟合曲线')
"""
结果
播放量和收藏量的拟合一次多项式:
0.0101 x + 8.94e+05
R方: 0.7061729401328387
播放量和收藏量的拟合一次多项式:
0.009856 x + 1.704e+05
R方: 0.6546135686415642
"""
|
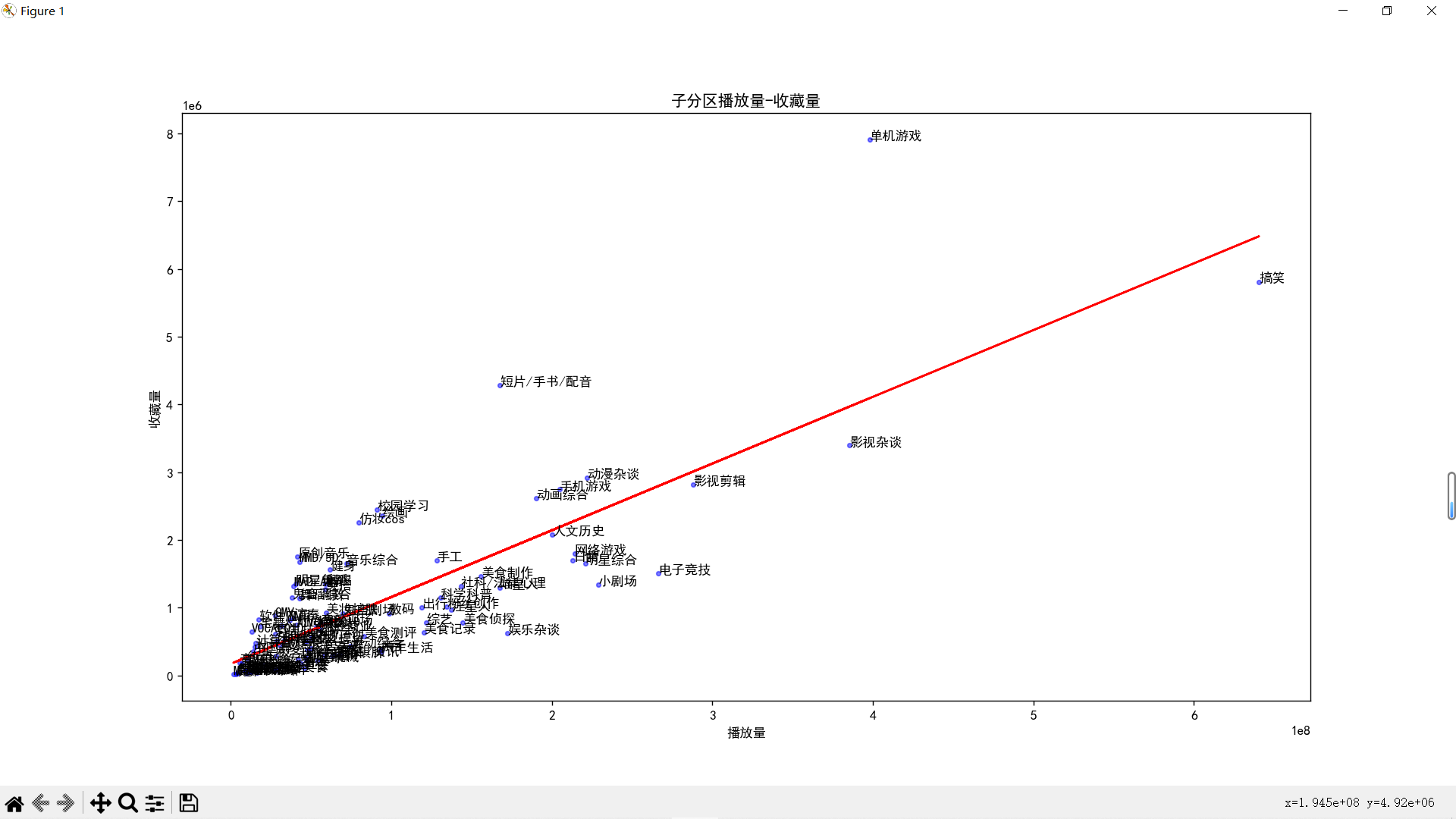
再放大点看以下左下角:
那么:
- 拟合曲线上方的点代表的视频分区的收藏率高于平均水平,这可能意味着这些视频分区有更高的用户忠诚度或者更好的内容质量。也许这些视频分区提供了一些硬核的内容,比如专业的知识、深入的分析、有价值的信息、值得回味的艺术等,让用户觉得值得收藏和回看。
- 拟合曲线下方的点代表的视频分区的收藏率低于平均水平,这可能意味着这些视频分区有更低的用户忠诚度或者更差的内容质量。也许这些视频分区提供了一些轻松娱乐的内容,比如搞笑的段子、热门的话题、有趣的现象等,让用户觉得只需观看一次就够了,没有必要收藏和回看。
当然,以上只是简单的分析,并不严谨,切勿当真
