上一步完成了Spark远程连接Hive的测试:数据仓库之Spark远程连接Hive | 62bit的秘密基地
这一步是StructuredStreaming写hive动态分区表
准备工作
启动hiveserver2和hive元数据管理服务
在hive目录中
1
2
| bin/hiveserver2
bin/hive --service metastore
|
启动Kafka集群
分区规则
按照时间来动态分区
pubdata字段中的数据都是 xxxx-xx-xx 当日时间 这种形式
我想要按照年份(year)和本年第几周(week)来做动态分区表
先将 xxxx-xx-xx 当日时间 拆分成 xxxx-xx-xx 和 当日时间 的形式,命名为date和time
1
2
| val df2 = df.withColumn("date",split(col("pubdate"), " ").getItem(0))
.withColumn("time", split(col("pubdate"), " ").getItem(1))
|
然后将date再分为year和week,使用weekofyear函数
1
2
| val df3 = df2.withColumn("year",split(col("date"), "-").getItem(0))
.withColumn("week",weekofyear(to_date(col("date"),"yyyy-MM-dd")))
|
代码编写
将消费Kafka的代码和连接Hive的代码整合起来,在加上写动态分区表的代码
其中KafkaConsumer来自之前的博客:数据仓库之Spark Structured Streaming实时消费Kafka | 62bit的秘密基地
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| import java.util.concurrent.TimeUnit
import org.apache.spark.SparkConf
import org.apache.spark.sql.functions.{col, split, to_date, weekofyear}
import org.apache.spark.sql.{SparkSession, functions}
import org.apache.spark.sql.streaming.{OutputMode, Trigger}
object StructuredStreamingFromKafka2Hive {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("StructuredStreamingFromKafka2Hive")
.setMaster("local[*]")
val spark = SparkSession.builder().config(conf)
.config("hive.metastore.uris","thrift://192.168.52.120:9083")
.enableHiveSupport()
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
val df = KafkaConsumer.readKafka2DF(spark,"bili","earliest")
val date_time_DF = df.withColumn("date",split(col("pubdate"), " ").getItem(0))
.withColumn("time", split(col("pubdate"), " ").getItem(1))
date_time_DF.printSchema()
val year_week_DF = date_time_DF.withColumn("year",split(col("date"), "-").getItem(0))
.withColumn("week",weekofyear(to_date(col("date"),"yyyy-MM-dd")))
year_week_DF.printSchema()
val ws = year_week_DF.writeStream
.outputMode(OutputMode.Append())
.format("orc")
.option("format", "append")
.trigger(Trigger.ProcessingTime(10,TimeUnit.SECONDS))
.option("checkpointLocation","hdfs://192.168.52.100:8020/tmp/offset/test/testStructuredStreamingFromKafka2Hive")
.partitionBy("year","week")
.toTable("test_db.bilibili")
ws.awaitTermination()
}
}
|
验证
查hive表,能查到
1
2
3
4
5
6
7
8
9
10
11
12
| def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("StructuredStreamingFromKafka2Hive")
.setMaster("local[*]")
val spark = SparkSession.builder().config(conf)
.config("hive.metastore.uris","thrift://192.168.52.120:9083")
.enableHiveSupport()
.getOrCreate()
val df = spark.sql("select * from test_db.bilibili")
df.show()
spark.close()
}
|

再去看一下hdfs上有没有分区表
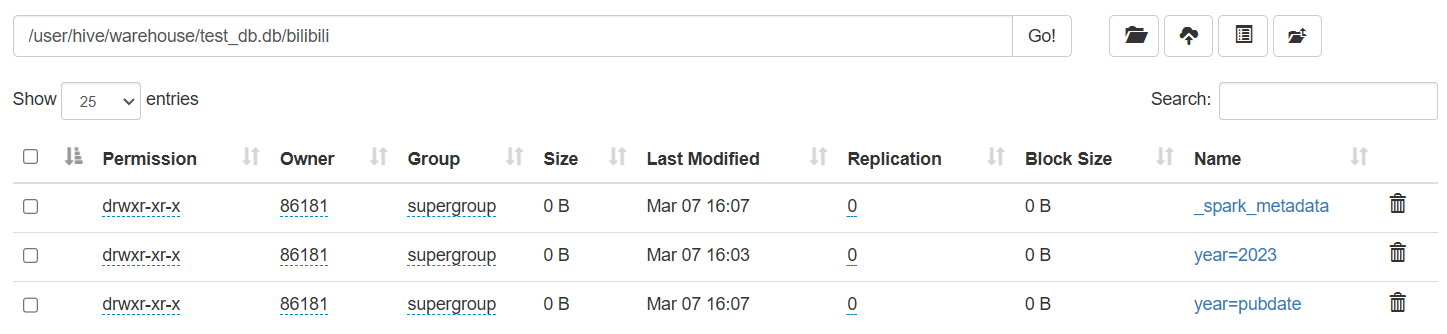
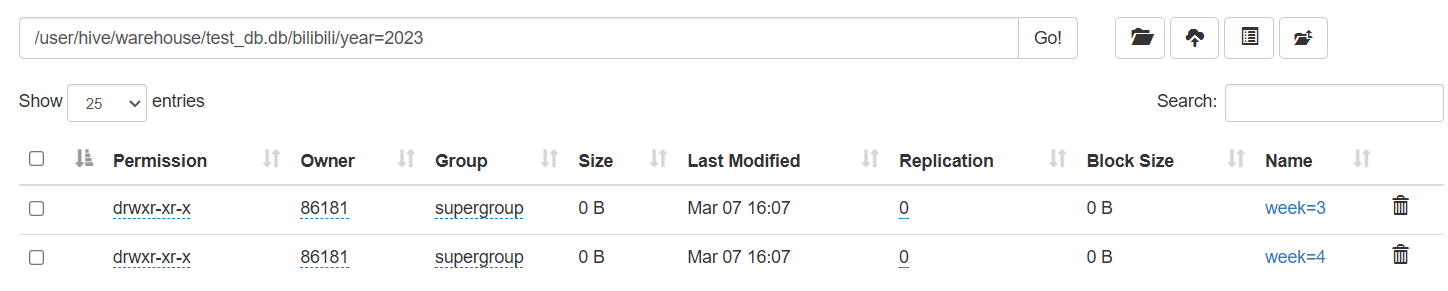
多了一个year=pubdate,是因为数据写入kafka时把header也当成数据写入了
从头消费Kafka验证了一下,猜想成立
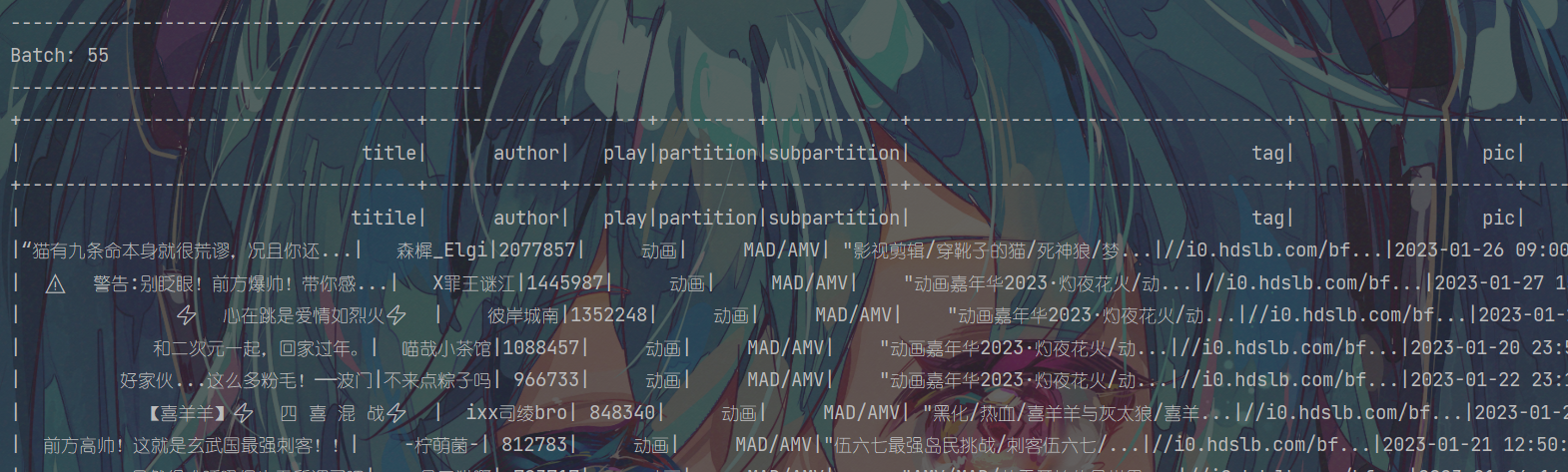
之前留下的坑
之前在数据仓库之Spark Structured Streaming实时消费Kafka | 62bit的秘密基地留下了一个坑,数据有可能错位了,在这时要记得过滤掉无效的数据
1
2
3
4
5
|
val filterDF = df
.withColumn("play",col("play").cast(IntegerType))
.filter(col("play").isNotNull)
|
加上这段代码后,顺便也解决了header被当成数据的问题
遇到的坑
weekofyear函数只能传入日期,我一开始传入的是字符串,要把字符串转成日期再传入
文件header被当成数据了,在加了判断数据有没有错位的代码后,不攻自破了
