上一步完成了SparkStructuredStreaming实时消费Kafka:数据仓库之Spark Structured Streaming实时消费Kafka | 62bit的秘密基地
首先在hive中创建一个表用于测试
1 2 3 4 5 6 7 8 CREATE DATABASE test_db; USE test_db; CREATE TABLE test( id int, name string ) ROW FROMAT DELIMITED FIELDS TERMINATED BY ','; INSERT INTO TABLE test VALUES(1, 'zhangsan');
Hive踩坑——使用逗号分隔符注意事项 - 代码先锋网 (codeleading.com)
开启hiveserver2和hive元数据服务
1 2 bin/hiveserver2 bin/hive --service metastore
导包
1 2 3 4 5 <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-hive_2.12</artifactId > <version > 3.2.0</version > </dependency >
写测试代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession object SparkConnectHiveTest def main Array [String ]): Unit = { val conf = new SparkConf () .setAppName("StructuredStreamingFromKafka2Hive" ) .setMaster("local[*]" ) val spark = SparkSession .builder().config(conf) .config("hive.metastore.uris" ,"thrift://192.168.52.120:9083" ) .enableHiveSupport() .getOrCreate() val df = spark.sql("select * from test_db.test" ) df.show() spark.close() } }
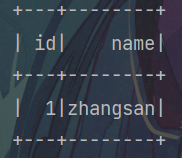
查到了数据,说明连接成功
遇到的坑:连接的时候不知道怎么写配置信息
解决方案:How to Connect Spark to Remote Hive - Spark By {Examples} (sparkbyexamples.com)