上一步完成了数据接入:数据仓库之数据接入 | 62bit的秘密基地
这一步先尝试以下Spark Structured Streaming实时消费kafka
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| import org.apache.spark.SparkConf
import org.apache.spark.sql.streaming.{OutputMode, Trigger}
import org.apache.spark.sql.{DataFrame, SparkSession}
import com.alibaba.fastjson.JSON
object KafkaConsumer {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("StructuredStreamingFromKafka").setMaster("local[*]")
val spark = SparkSession.builder().config(conf).getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
val df = readKafka2DF(spark,"bili","earliest")
df.printSchema()
val query = df.writeStream
.outputMode(OutputMode.Append())
.format("console")
.trigger(Trigger.ProcessingTime(5000))
.option("checkpointLocation","hdfs://192.168.52.100:8020/tmp/offset/test/kafka_offset")
.start()
query.processAllAvailable()
}
def readKafka2DF(spark: SparkSession, topic: String, startingOffsets: String): DataFrame = {
import spark.implicits._
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers","192.168.52.100:9092")
.option("subscribe", topic)
.option("startingOffsets", startingOffsets)
.option("encoding", "utf-8")
.load()
df.selectExpr("CAST(value AS STRING)")
.map(row => {
val line = row.getAs[String]("value")
val rawJson = JSON.parseObject(line)
val message = rawJson.getString("message")
val msgArray = message.split(",")
msgArray
})
.filter(_.length == 12)
.map(array => (array(0),array(1),array(2),array(3),array(4),array(5)
,array(6),array(7),array(8),array(9),array(10),array(11)))
.toDF("title", "author", "play", "partition", "subpartition", "tag", "pic","pubdate", "arcurl", "review", "video_review", "favorites")
}
}
|
Trigger触发器
spark的dataframe的writeStream中的trigger是用来设置流查询的触发器的。触发器可以控制流查询的执行频率和模式。可以选择以下几种触发器之一:
- processingTime: 根据处理时间间隔,定期运行一个微批次查询,例如’5 seconds’,’1 minute’。
- once: 只处理一个批次的数据,然后终止查询。
- continuous: 根据检查点间隔,运行一个连续查询,例如’5 seconds’,’1 minute’。
- availableNow: 处理所有可用的数据,可能有多个批次,然后终止查询。
如果不设置任何触发器,那么spark会尽可能快地运行查询,相当于设置了processingTime=’0 seconds’。
writeStream.processAllAvailable

import spark.implicits._ 是什么
import spark.implicits._是用来导入spark的一些隐式转换和方法的。spark是一个SparkSession类型的对象,它包含了一个implicits对象,这个对象继承了SQLImplicits类,提供了一些功能,例如:
- 将scala对象转换为dataset或dataframe(通过toDS或toDF方法)。
- 将”$name”转换为Column(用于选择或过滤数据)。
导入spark.implicits._后,这些功能就可以在当前作用域中隐式地使用,不需要显式地调用。这样可以简化spark的编程和操作。
What is imported with spark.implicits._? - Stack Overflow
遇到的坑
可以在hdfs上看到offset文件
但是打印出来的batch是空的
找了很久原因,是因为代码中的filter有问题,它保留长度大于12的数据,而我消费的数据理论上只有12个字段,最后发现是数据中本来就带有逗号,按照逗号切割时把数据给切断了,导致所有数据的长度都大于12
暂时能想到的解决方案就是更换爬虫中写入数据的分隔符
去掉filter之后,看到可以消费到数据
现在的状态就是能消费到数据,但是逗号的问题没解决
解决方案
观察数据发现只有tag字段带有英文逗号,之前的代码会把tag字段切开
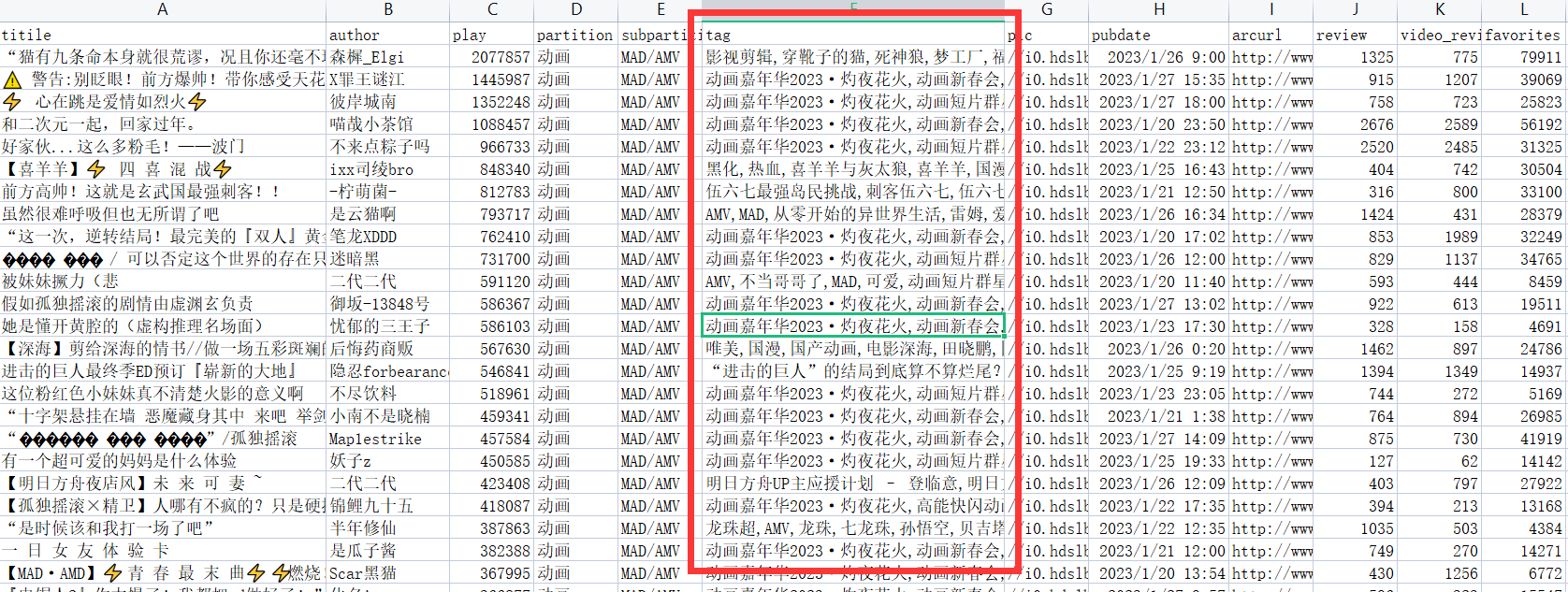
更改代码
1
2
3
4
5
6
7
8
9
10
11
12
| df.selectExpr("CAST(value AS STRING)")
.map(row => {
val line = row.getAs[String]("value")
val rawJson = JSON.parseObject(line)
val message = rawJson.getString("message")
val msgArray = message.split(",")
msgArray
})
.map(array => (array(0),array(1),array(2),array(3),array(4)
,array.slice(5,array.length - 6).mkString("/")
,array(array.length - 6),array(array.length - 5),array(array.length - 4),array(array.length - 3),array(array.length - 2),array(array.length - 1)))
.toDF("title", "author", "play", "partition", "subpartition", "tag", "pic","pubdate", "arcurl", "review", "video_review", "favorites")
|
把被切开的tag字段手动组合起来,用“/”作为分隔符
然后再次测试,可以正常消费到数据了!
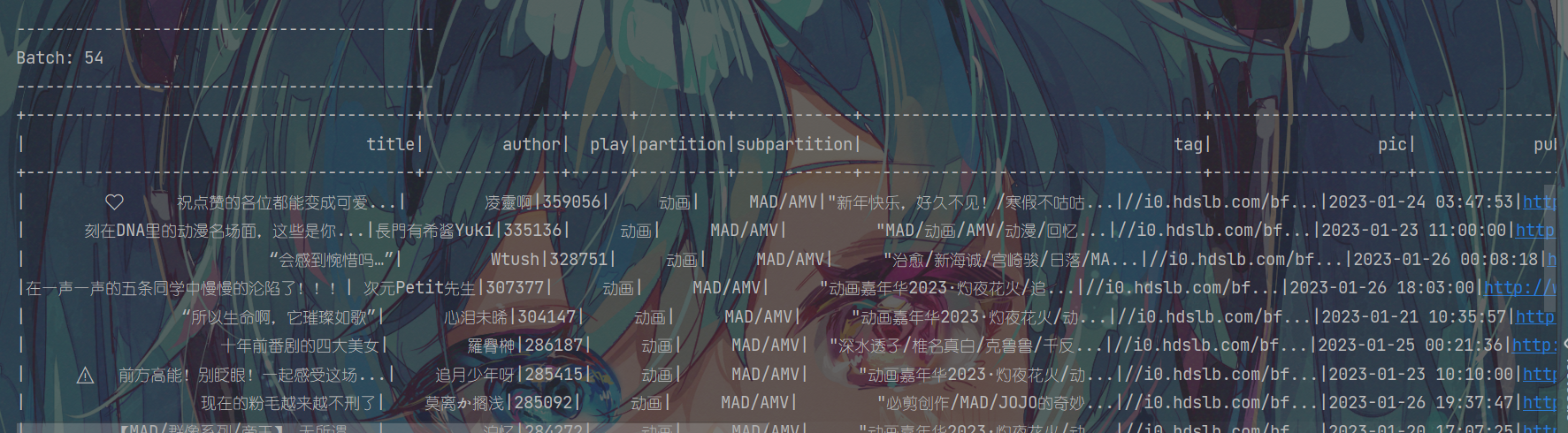
缺陷
这个方法只适用于有一个字段带有英文逗号的情况,如果title字段中也带有英文逗号,显然会出错,还需要在后面数据从ODS到DWD时过滤一下,比如判断play字段是否可以转为数字,转不了说明前面title字段被切开了,数据错位了
