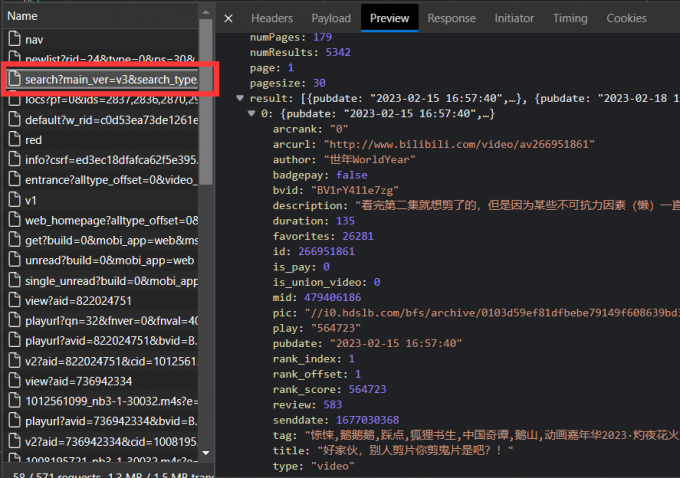
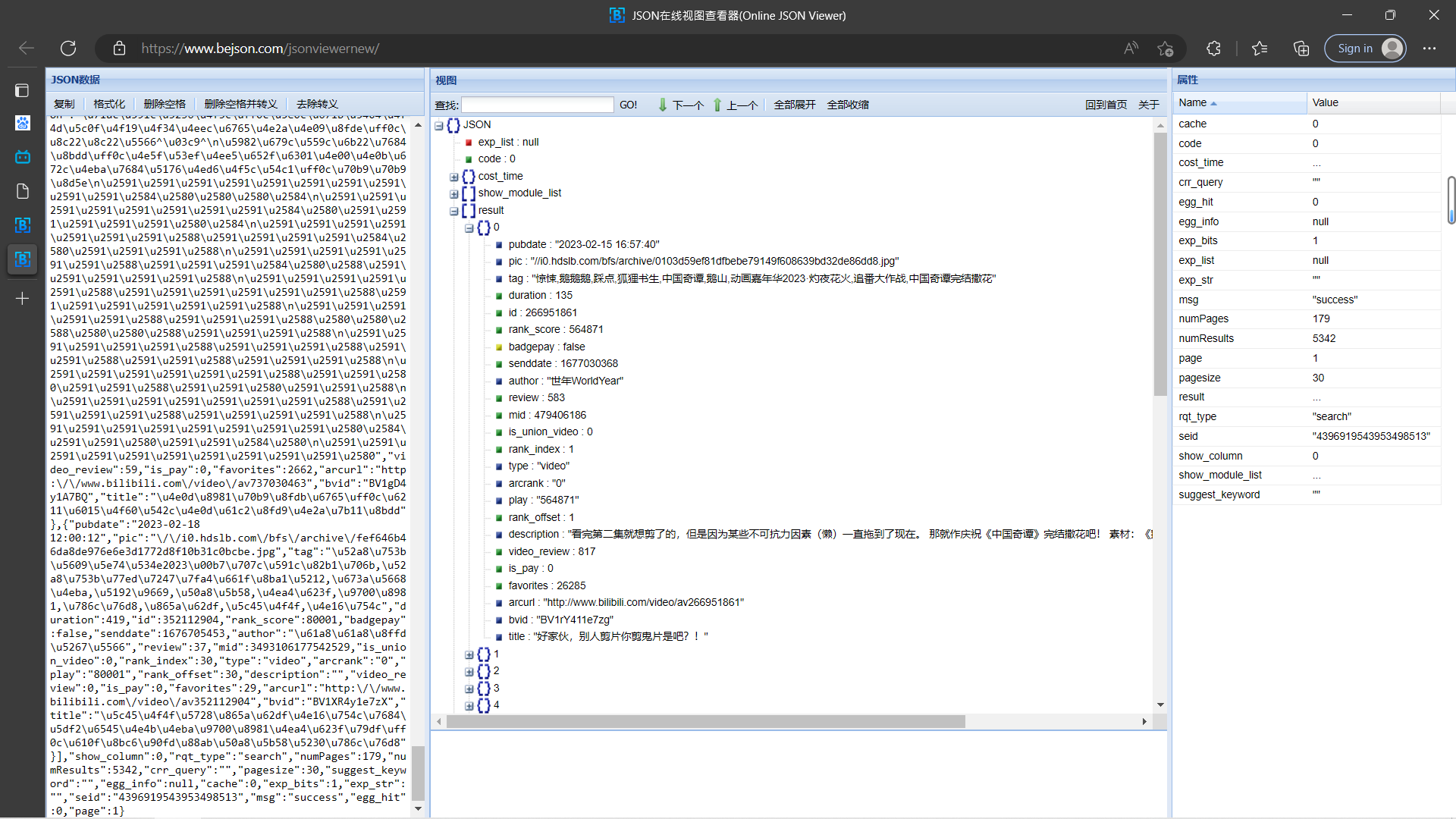
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| import requests
import json
import csv
f = open("E:\\bili_csv\\bili.csv", mode='a', encoding="utf-8-sig", newline="")
csv_writer = csv.DictWriter(f, fieldnames = ["titile", "author", "play", "partition", "tag", "pic","pubdate", "arcurl", "review", "video_review", "favorites"])
csv_writer.writeheader()
cate_id = [24, 25, 47, 210, 86, 253, 27, 22, 26, 126, 216, 127, 20, 198, 199, 200, 154, 156, 71, 241, 242, 137, 95, 230, 231, 232, 233, 76, 212, 213, 214, 215, 17, 171, 172, 65, 173, 121, 136, 19, 28, 31, 59, 30, 29, 193, 243, 244, 130, 182, 183, 85, 184, 201, 124, 228, 207, 208, 209, 229, 122, 203, 204, 205, 206, 138, 254, 250 ,251, 239, 161, 162, 21, 218, 219, 222, 221, 220, 75, 245, 246, 247, 248, 240, 227, 176, 157, 252, 158, 159, 235, 249, 164, 236, 237, 238]
partitions = ["动画", "动画", "动画", "动画", "动画", "动画", "动画", "鬼畜", "鬼畜", "鬼畜", "鬼畜", "鬼畜", "舞蹈", "舞蹈", "舞蹈", "舞蹈", "舞蹈", "舞蹈", "娱乐", "娱乐", "娱乐", "娱乐", "科技", "科技", "科技", "科技", "科技", "美食", "美食", "美食", "美食", "美食", "游戏", "游戏", "游戏", "游戏", "游戏", "游戏", "游戏", "游戏", "音乐", "音乐", "音乐", "音乐", "音乐", "音乐", "音乐", "音乐", "音乐", "影视", "影视", "影视", "影视", "知识", "知识", "知识", "知识", "知识", "知识", "知识", "知识", "资讯", "资讯", "资讯", "资讯", "生活", "生活", "生活", "生活", "生活", "生活", "生活", "生活", "动物圈", "动物圈", "动物圈", "动物圈", "动物圈", "动物圈", "汽车", "汽车", "汽车", "汽车", "汽车", "汽车", "汽车", "时尚", "时尚", "时尚", "时尚", "运动", "运动", "运动", "运动", "运动", "运动"]
tags = ["MAD/AMV", "MMD/3D", "短片/手书/配音", "手办/模玩", "特摄", "动漫杂谈", "动画综合", "鬼畜调教", "音MAD", "人力VOCALOID", "鬼畜剧场", "教程演示", "宅舞", "街舞", "明星舞蹈", "中国舞", "舞蹈综合", "舞蹈教程", "综艺", "娱乐杂谈", "粉丝创作", "明星综合", "数码", "软件应用", "计算机技术", "科工机械", "极客DIY", "美食制作", "美食侦探", "美食测评", "田园美食", "美食记录", "单机游戏", "电子竞技", "手机游戏", "网络游戏", "桌游棋牌", "GMV", "音游", "Mugen", "原创音乐", "翻唱", "演奏", "VOCALOID", "音乐现场", "MV", "乐评盘点", "音乐教学", "音乐综合", "影视杂谈", "影视剪辑", "小剧场", "预告/资讯", "科学科普", "社科/法律心理", "人文历史", "财经商业", "校园学习", "职业职场", "设计/创意", "野生技能协会", "热点", "环球", "社会", "资讯综合", "搞笑", "亲子", "出行", "三农", "家居房产", "手工", "绘画", "日常", "喵星人", "汪星人", "小宠异宠", "野生动物", "动物二创", "动物综合", "赛车", "改装玩车", "新能源车", "房车", "摩托车", "购车攻略", "汽车生活", "美妆护肤", "仿妆cos", "穿搭", "时尚潮流", "篮球", "足球", "健身", "竞技体育", "运动文化", "运动综合"]
for idx in range(0, 96):
partition = partitions[idx]
id = cate_id[idx]
tag = tags[idx]
for page in range(1, 2)
url = "https://s.search.bilibili.com/cate/search?main_ver=v3&search_type=video&view_type=hot_rank©_right=-1&new_web_tag=1&order=click&cate_id=" + str(id) + "&page=" + str(page) + "&pagesize=100&time_from=20230120&time_to=20230127"
response = requests.get(url)
d0 = json.loads(response.content)
for i in range(0, 100):
try:
print(tag + " " + str(page) + " " + str(i))
play = d0["result"][i]["play"]
author = d0["result"][i]["author"]
title = d0["result"][i]["title"]
review = d0["result"][i]["review"]
pubdate = d0["result"][i]["pubdate"]
favorites = d0["result"][i]["favorites"]
arcurl = d0["result"][i]["arcurl"]
video_review = d0["result"][i]["video_review"]
pic = d0["result"][i]["pic"]
data = {"titile":title,
"author":author,
"play":play,
"partition":partition,
"tag":tag,
"pic":pic,
"pubdate":pubdate,
"arcurl":arcurl,
"review":review,
"video_review":video_review,
"favorites":favorites}
csv_writer.writerow(data)
except:
print("out of limit")
continue
|